


Reinforcement learning-based attitude control for a quadrotor UAV system with performance constraints
 0
0 Abstract
In this paper, a fuzzy logic-based fault-tolerant attitude control strategy is proposed for the attitude tracking of a quadrotor unmanned aerial vehicle (UAV) subject to actuator faults. The attitude dynamics of the quadrotor are represented using modified Rodrigues parameters. Inspired by the biological trial-and-error mechanism that reinforcement learning (RL) emulates, the proposed method is developed by integrating fuzzy logic systems (FLSs) with RL. To enhance the autonomous learning capability and tracking performance of the UAV system, actor–critic (AC) learning is introduced as an effective RL method. A cost function defined in terms of tracking errors is introduced, and an FLS is incorporated into the critic to approximate the cost function for performance evaluation. The actor is responsible for generating the control input based on the critic signals. Concurrently, another FLS is employed to approximate system uncertainties and actuator bias faults. Furthermore, to meet increasingly stringent control requirements, performance constraints are imposed to guarantee prescribed tracking performance. The system stability and convergence of tracking errors are analyzed using Lyapunov stability theory. Finally, simulations are conducted to verify the effectiveness of the proposed adaptive fault-tolerant attitude control scheme.
Keywords
1. INTRODUCTION
Inspired by the exceptional agility and adaptability of biological flyers, the development of highly autonomous and agile aerial robotics has garnered significant attention in recent years [1–3]. As a representative platform in this field, the quadrotor unmanned aerial vehicle (UAV) is distinguished by its compact structure, high maneuverability, and vertical takeoff and landing capability [4–6]. However, quadrotor UAV systems are inherently highly nonlinear, strongly coupled, and subject to significant model uncertainties [7]. In practical applications, UAV system performance can also be adversely affected by external disturbances, sensor inaccuracies, and actuator faults, which pose significant challenges for conventional control methods [8]. Intelligent adaptive control offers the advantage of strong resilience and autonomous decision-making capability, enabling the system to maintain stable performance in complex environments. Consequently, adaptive control strategies offer a promising solution to these challenges.
In practical scenarios, actuator faults have detrimental effects on quadrotor UAV operations. These faults can significantly degrade control performance and even lead to system instability or mission failure. To address the challenges, extensive research has been conducted, resulting in the development of various control strategies [9–11]. For instance, Zhao et al. employed reinforcement learning (RL) to obtain an optimal control policy for suppressing actuator faults [9]. Furthermore, Ma et al. proposed a distributed adaptive method that compensates for actuator faults with gain uncertainties and structural changes, which can ensure stable UAV–unmanned ground vehicle (UGV) formation [11]. However, most existing methods rely on accurate models and primarily focus on efficiency loss, while neglecting concurrent bias faults. Thus, it is essential to develop fault-tolerant control schemes capable of addressing simultaneous multiplicative and additive faults.
Fuzzy logic systems (FLSs) are suitable for uncertain and highly nonlinear systems, because they can approximate complex nonlinear functions without requiring an accurate mathematical model. Moreover, their rule-based structure provides interpretability and flexibility in controller design, which facilitates the effective handling of external disturbances and system uncertainties [12–14]. Zhang et al. employed an FLS to approximate unknown nonlinear dynamics over a compact set within an ideal controller framework [15]. Additionally, Yu et al. utilized an FLS to approximate unknown nonlinearities and estimate unmeasurable states, achieving finite-time probabilistic stability under stochastic disturbances [16]. Consequently, FLS can serve as an effective tool for addressing model uncertainties and complex nonlinear dynamics in quadrotor UAV systems.
As a key realization of biomimetic intelligence, RL mimics the trial-and-error learning capability of biological systems[17–19]. Through continuous interaction with the environment, RL can learn control policies online, thereby enhancing decision-making performance. To meet the increasing demand for autonomy and intelligence, actor–critic (AC) learning has emerged as an effective RL-based approach. This method employs a specialized architecture consisting of two interacting networks that evaluate the value function and optimize the control policy, enabling online adaptive control [20–23]. For example, Ouyang et al. proposed an adaptive coordinated control method based on an AC framework to address the optimal tracking control problem of dual-arm robots [24]. Similarly, AC learning has been utilized to handle unknown system uncertainties, where the critic approximates the performance cost and the actor generates compensation control [25]. In addition, odd-numbered symmetric actuators and even-numbered critics have been introduced to address instability and asymmetry problems in quadrotor flight control based on AC learning [26]. These studies demonstrate that the AC architecture, inspired by RL, can learn approximately optimal control policies through online interaction without relying on an explicit system model. As such, it significantly enhances autonomous learning and optimization performance, thereby fulfilling the overarching requirements for autonomy and intelligence.
Prescribed performance, as a class of performance constraints, addresses control tasks with explicit transient and steady-state requirements. A prescribed performance function (PPF) is commonly employed to ensure that tracking error, convergence rate, and overshoot remain within predefined bounds [27–31]. For example, Yu et al. developed finite-time PPFs to transform distributed tracking errors into a new set of errors based on the transient and steady-state requirements[28]. Moreover, Li et al. integrated an improved performance function with a reduced-order K-filter to realize prescribed performance while relaxing initial state constraints [31]. Therefore, to meet the growing need for superior attitude control performance in UAV systems, prescribed performance strategies have become increasingly attractive and viable.
In this paper, we focus on the adaptive attitude tracking control problem for a quadrotor UAV subject to actuator faults. To enhance autonomous learning and optimization performance under such conditions, an adaptive fault-tolerant attitude control method integrating an FLS with RL is proposed. Furthermore, to satisfy increasingly stringent control requirements, a prescribed performance constraint is incorporated into the UAV system. Based on the above, the main contributions of this paper are shown as follows:
1. Compared with existing RL-based control schemes for quadrotor UAVs [9,20,26], the proposed RL-based fuzzy adaptive attitude control not only achieves optimized tracking control performance under prescribed performance constraints, but also avoids the adverse effects caused by actuator faults. By employing an FLS, the proposed approach achieves faster convergence due to simpler parameter tuning and fewer training iterations. In the proposed AC-based RL architecture, the critic component evaluates future performance and yields an evaluative signal, while the actor component generates an optimized reinforced control input that compensates for system uncertainties and actuator faults.
2. Different from existing fault-tolerant control methods for quadrotor UAVs [9,11], the proposed approach considers the simultaneous occurrence of actuator efficiency degradation faults and bias faults. Accordingly, a unified fault model is constructed to characterize these concurrent failures, which facilitates effective compensation for their combined effects.
The remainder of this paper is organized as follows. Section 2 presents the preliminary concepts and problem formulation. Section 3 shows the development of the proposed RL-based fault-tolerant attitude control strategy, along with the corresponding stability analysis. Section 4 presents simulation studies to validate the effectiveness of the proposed approach. Finally, Section 5 concludes the paper.
Notation: Throughout this paper,
2. PRELIMINARIES
2.1. Kinematics and dynamics of the UAV attitude system with actuator faults
The structural diagram of a quadrotor UAV is shown in Figure 1, which includes two coordinate frames: the inertial frame OXYZ and the body-fixed frame
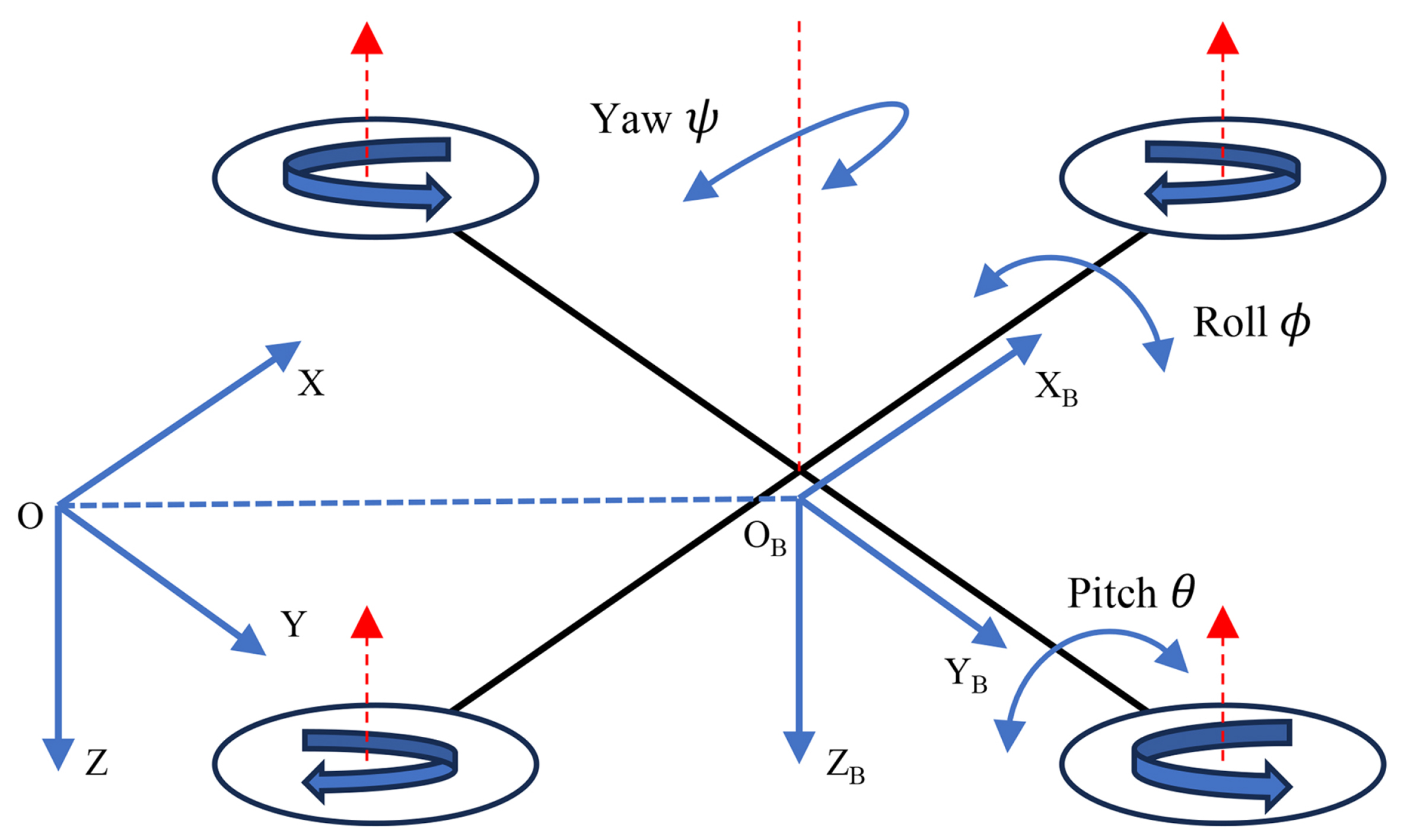
Figure 1. Structural diagram of a quadrotor UAV. UAV: Unmanned aerial vehicle.
where
It should be noted that the MRP representation possesses a coordinate singularity at
where
which satisfy the following properties.
Property 1[32].
where
Property 2[33].
In this paper, the actuator fault model, which encompasses efficiency loss and bias-type faults, is expressed as[34]
where
By incorporating Equation (9) into Equation (4), the system dynamics under actuator faults can be rewritten as
where
In summary, Equation (9) indicates that the i-th actuator fails from time
Moreover, it should be noted that faults in practical systems are difficult to repair or eliminate. Therefore, the transition from a fault-free state to a faulty state is considered unidirectional. In addition, each actuator is assumed to experience at most one fault.
2.2. Prescribed performance
To enhance attitude tracking performance, a prescribed performance constraint is applied to the UAV system to confine the tracking error within a predefined envelope, thereby ensuring that both transient and steady-state performance requirements are satisfied.
Defintion 1[29]. A continuous function
(1)
(2)
where
where
2.3. FLS
An FLS consists of four components: the fuzzifier, the fuzzy inference engine, the defuzzifier, and the knowledge base. The knowledge base comprises a set of IF-THEN fuzzy rules. The i-th rule is described as follows[12]:
where
The fuzzy basis function is defined as
Define
Lemma 1[12]. For any continuous function
where
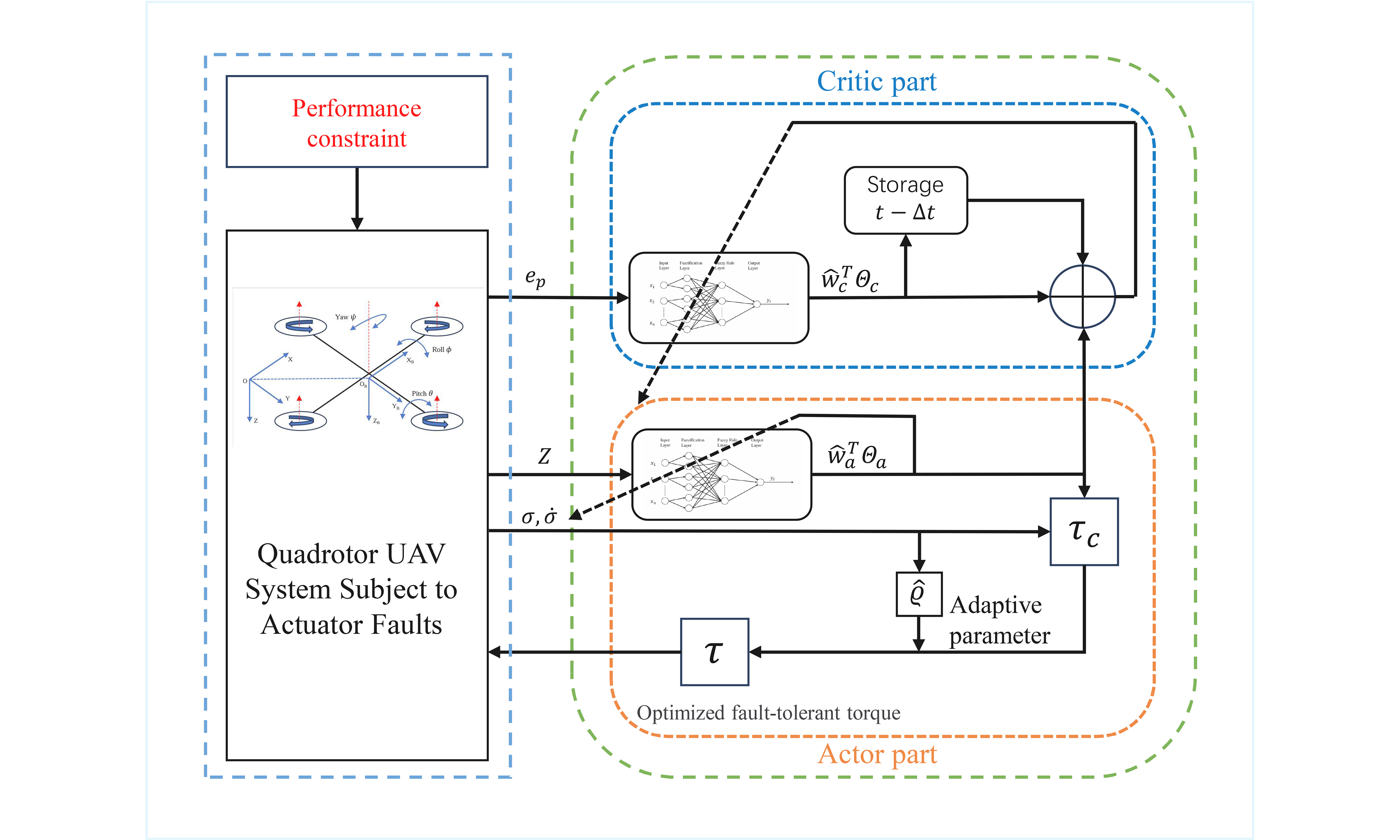
3. AC RL-BASED ADAPTIVE ATTITUDE CONTROL DESIGN
3.1. Critic design
For the quadrotor UAV system, let
The long-term tracking cost function is defined as
where T denotes the time constant, and
Due to dependence on future system information, directly solving
where
According to Equations (18) and (19), the continuous-time temporal difference error is defined as
where
where
Considering the symmetry of the updating law Equation (21) and that the boundary condition for
where
Then, we obtain
According to the gradient method, the critic updating law can be rewritten as
In addition, to enhance the robustness of the algorithm against system uncertainties and external disturbances, a 𝜉-correction term is incorporated. This term ensures the boundedness of the estimated parameters even in the absence of the strict persistent excitation (PE) condition[35]. Therefore, the final updating law for the critic FLS is given by
3.2. Actor design
To address the prescribed performance constraint, an error transformation function is introduced to reformulate it into an unconstrained equivalent form. To this end, a smooth and strictly increasing function
where Z is the transformed error. The error transformation function is defined as
Because
where
where
Accordingly, the Lyapunov function candidate
The time derivative of
According to Equation (17), we have
Thus, the virtual control variable
where
where
Taking the time derivative of
To ensure the negative definiteness of
Due to model uncertainties, the exact values of
To analyze the closed-loop stability and derive the adaptive mechanisms, the following Lyapunov function candidate
where
In order to handle the relationship between the vector inner product and the matrix trace during the derivation, the following lemma is introduced:
Lemma 2. For any two vectors
Taking the time derivative of
Applying Lemma 2 with
Thus,
To eliminate the indefinite terms associated with
Meanwhile, the actor component is augmented with an FLS, which not only approximates the uncertain nonlinear terms in the system dynamics but also accounts for bias faults. This design enables implicit and adaptive fault compensation. The ideal approximation performance of the actor FLS is expressed as
where
where
where
With the adaptive mechanism Equation (48) compensating for the actuator efficiency degradation, the remaining fault tolerance capability relies on the actor FLS. By treating the unknown bias fault
To realize this implicit compensation while simultaneously optimizing system performance, the objective of the actor FLS is to drive the estimated cost function
where
where
Since
where
Algorithm 1: Fuzzy Logic Fault-Tolerant Attitude Control via Reinforcement Learning 1: Initialize: 2: Define attitude model using MRPs 3: Initialize FLS parameters for actor and critic FLS 4: Set prescribed performance bounds 5: Initialize actor FLS weights 6: Set learning rates 7: Define performance transformation function 8: for each time step t = 1 to T do 9: Measure current UAV attitude 10: Compute tracking error: 11: Apply prescribed performance transformation: 12: 13: Define virtual control 14: Compute derivative error: 15: Actor FLS estimates control input (approximating 16: Apply fault-tolerant control law: 17: Apply control torque 18: Observe system response: 19: Critic component: 20: Compute cost signal 21: Approximate value function with critic FLS: 22: Compute temporal difference error using backward Euler approximation: 23: Update critic FLS weights: 24: Actor component: 25: Compute actor FLS update error: 26: Update actor FLS weights: 27: end for
Then, a theorem is obtained as follows.
Theorem 1 For a quadrotor UAV system subject to performance constraints and actuator faults, the proposed RL-based fuzzy adaptive fault-tolerant attitude control strategy ensures stability and tracking performance. The error signals
Remark 1 It is important to emphasize the forward invariance of the prescribed performance corridor. According to the Lyapunov analysis in Theorem 1, the candidate function
Proof: For a UAV system subject to performance constraints, the following Lyapunov function candidate is constructed
Based on Equations (37), (48) and (49), we obtain
To facilitate subsequent analysis, we introduce
Based on the updating law Equation (52), we have
where
The parameter
Define
According to Equation (26), the time derivative of
According to Equations (62) and (64), we can conclude that
where
with
Multiplying both sides of Equation (65) by
By integrating both sides of Equation (68), we obtain
According to Equations (58) and (69), there is
Therefore, the tracking error is ultimately bounded as
where
4. SIMULATION
In this section, simulations are conducted on a quadrotor UAV system to evaluate the proposed RL-based fuzzy adaptive fault-tolerant attitude control strategy.
In the simulation, the quadrotor UAV is subjected to actuator faults occurring at
where
In the simulation, the initial conditions are set as
To achieve the prescribed performance, appropriate constraints are imposed on the UAV system. According to Equations (11) and (12), the performance-related parameters are set as:
For the proposed RL-based adaptive attitude control, based on Equation (13), the relevant parameters of the membership functions are set as: the inputs are processed using tanh(·) and the centers
For the adaptive law used to compensate for actuator effectiveness, the learning rate matrix in Equation (48) is chosen as
Based on the above parameter settings, the proposed RL-based fault-tolerant attitude control performance is shown in Figures 2-6. The tracking errors of the UAV system with prescribed performance are illustrated in Figure 2A-C, which display the tracking errors
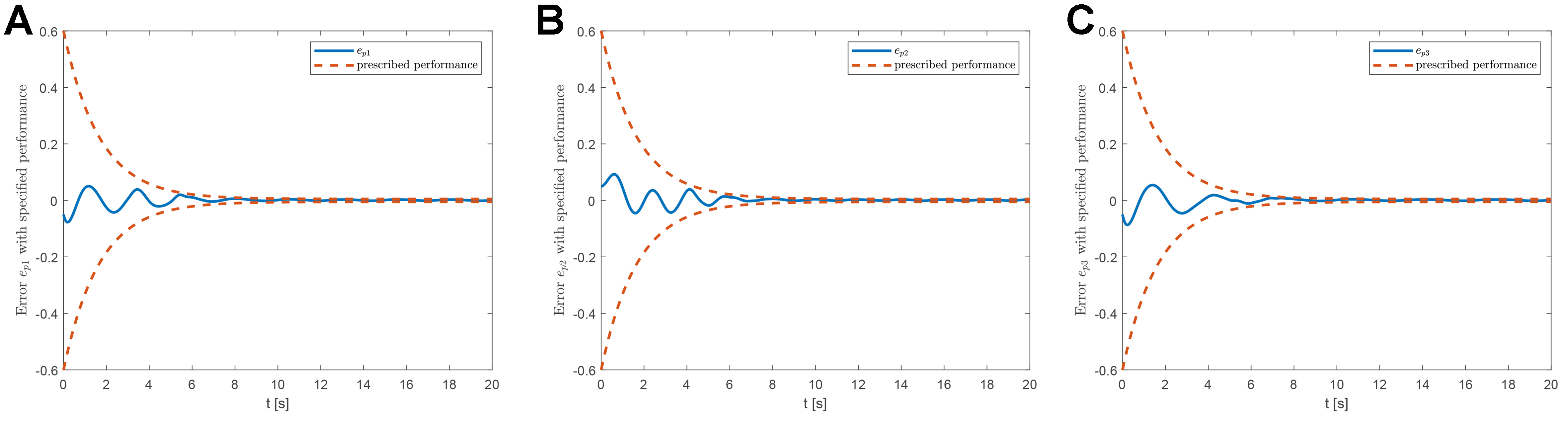
Figure 2. Tracking errors with prescribed performance under the proposed RL-based fault-tolerant attitude controller. (A) Attitude tracking error
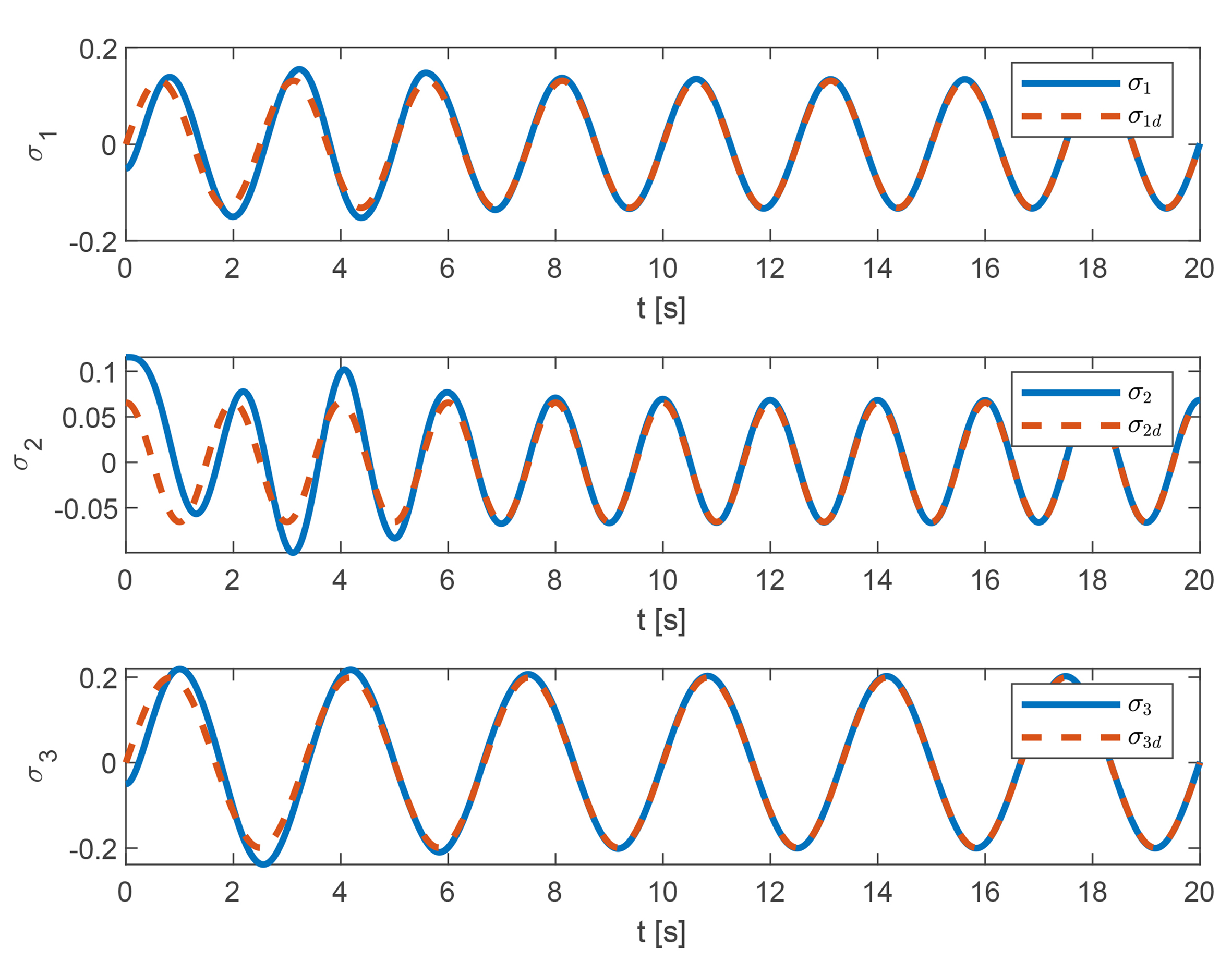
Figure 3. Attitude tracking performance under the proposed RL-based fault-tolerant attitude controller. RL: Reinforcement learning.
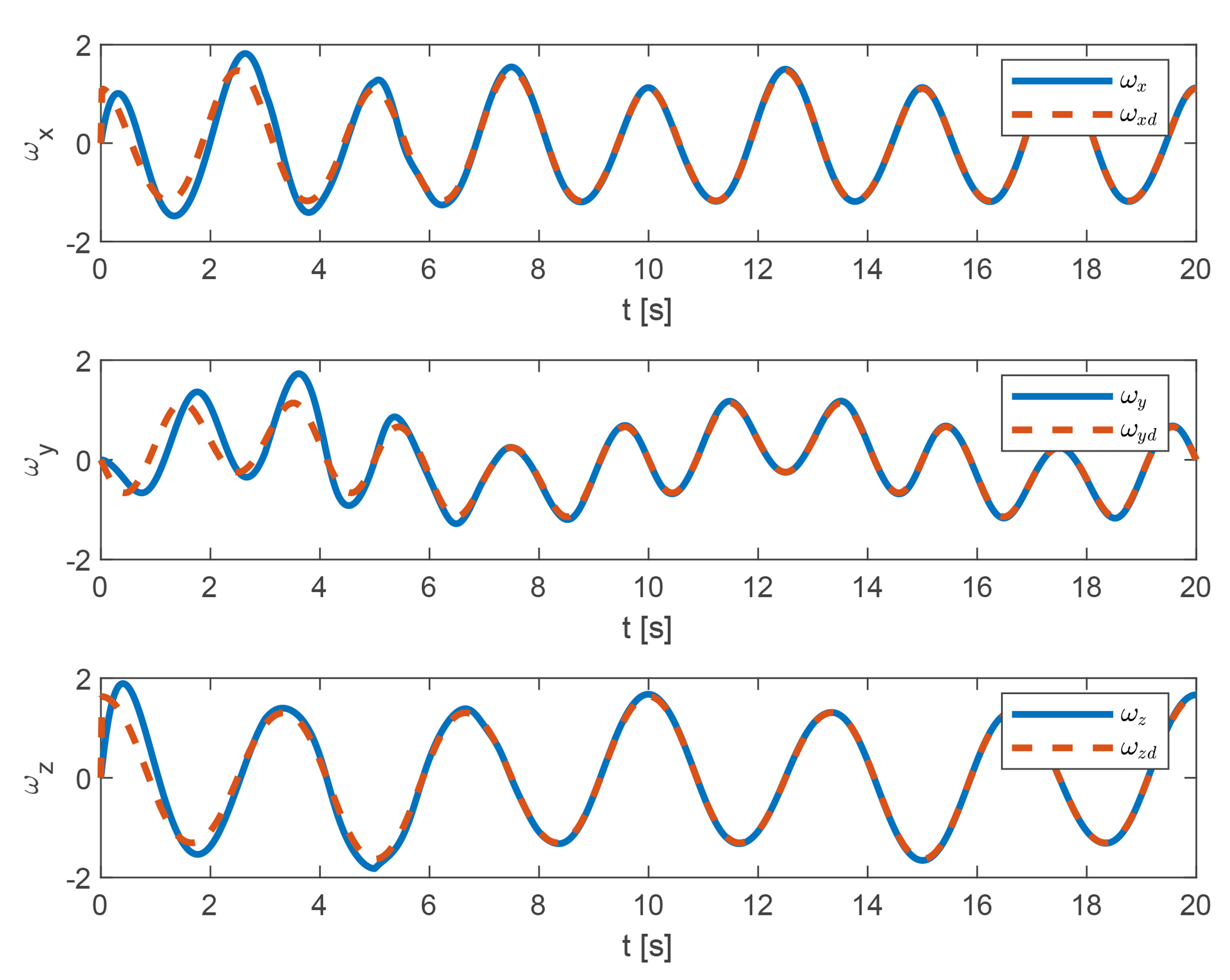
Figure 4. Angular velocity tracking performance of the quadrotor UAV. UAV: Unmanned aerial vehicle.
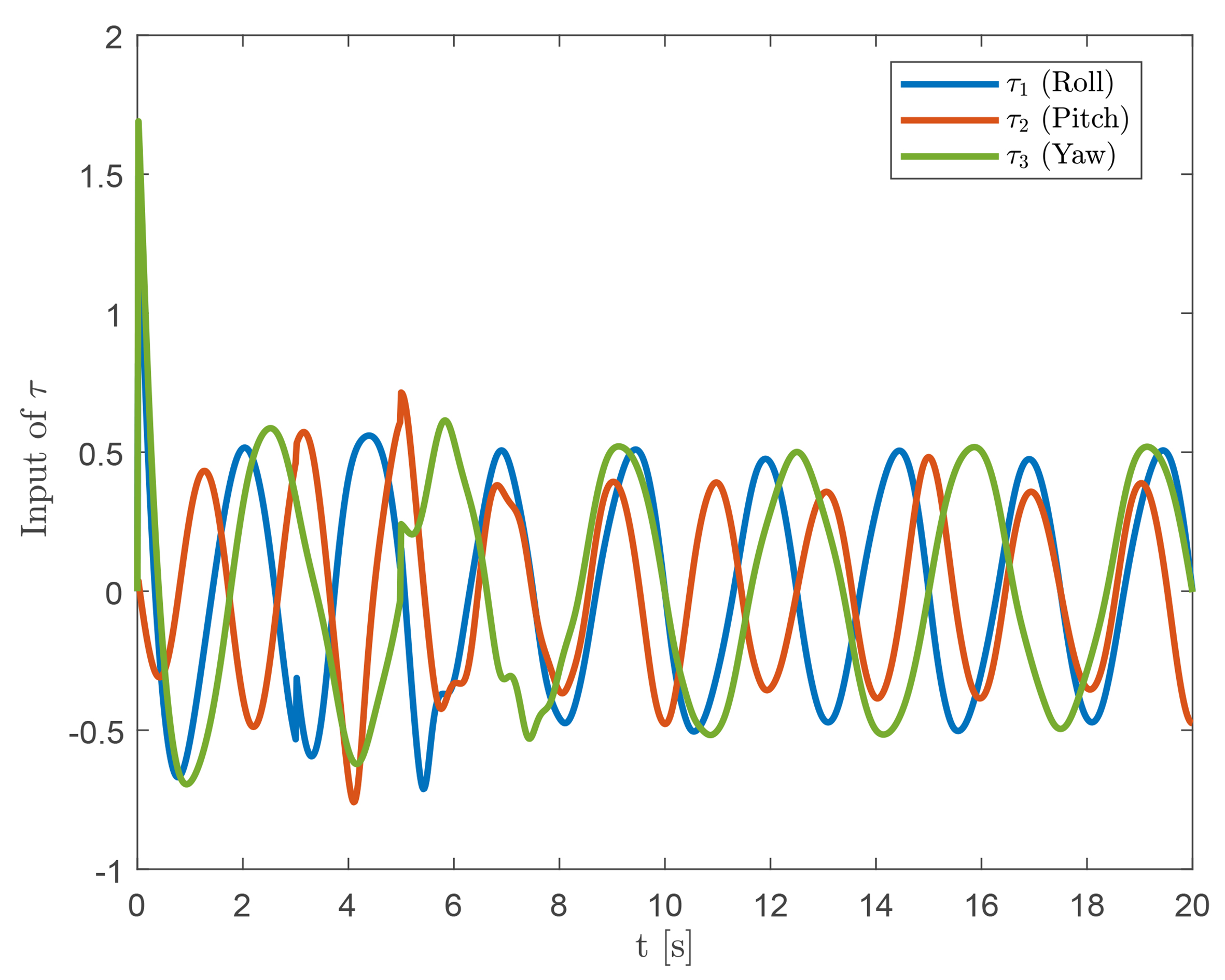
Figure 5. Control torque variation of the quadrotor UAV. UAV: Unmanned aerial vehicle.
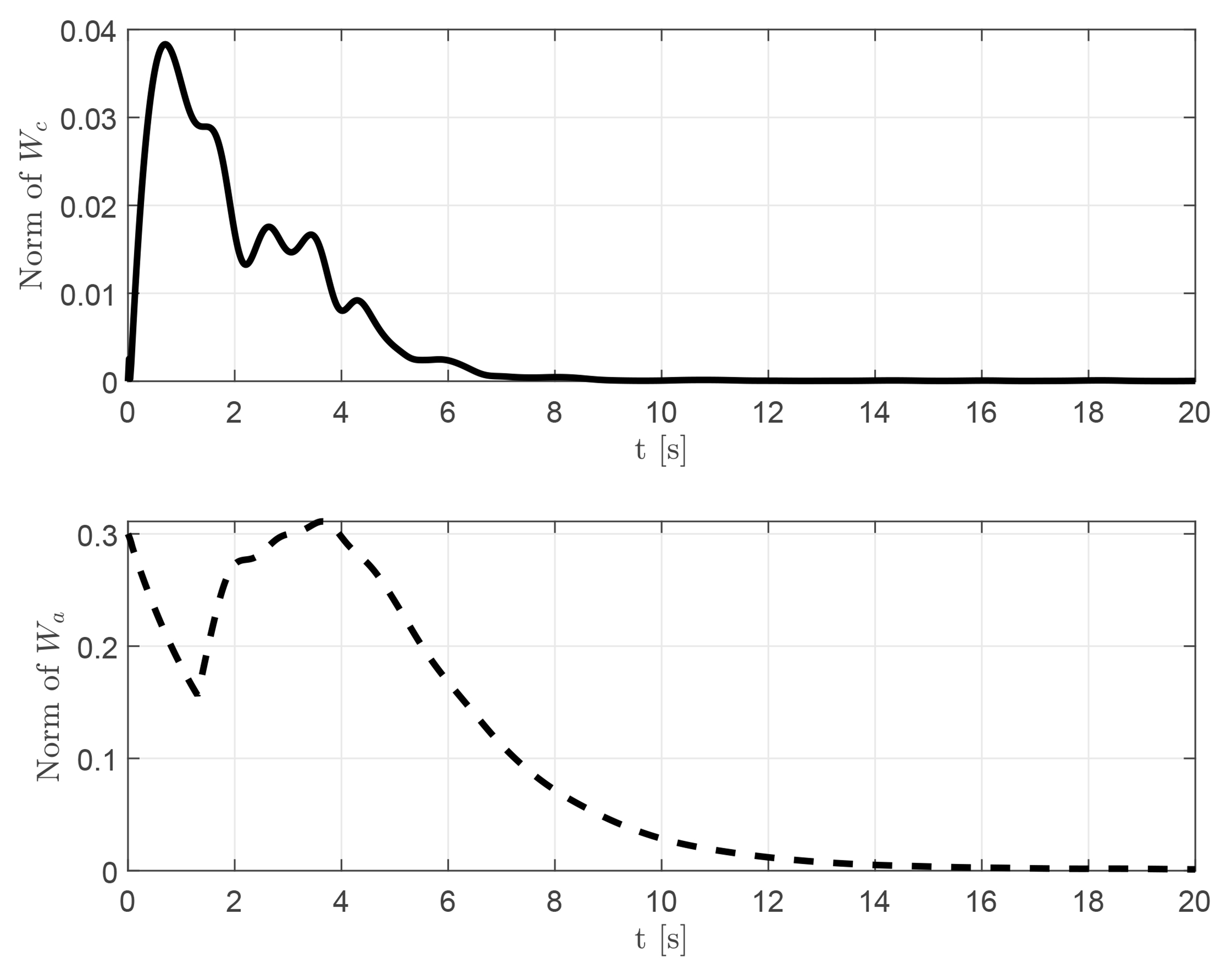
Figure 6. Norms of the critic and actor weight vectors (
Figure 3 shows the overall tracking performance of the UAV system after attitude angle transformation. The variables
To further demonstrate the superiority of the proposed RL-based fault-tolerant attitude control scheme, a conventional proportional-integral-derivative (PID) controller is implemented as a baseline for comparison on a quadrotor UAV system subject to performance constraints and actuator faults. The control torque
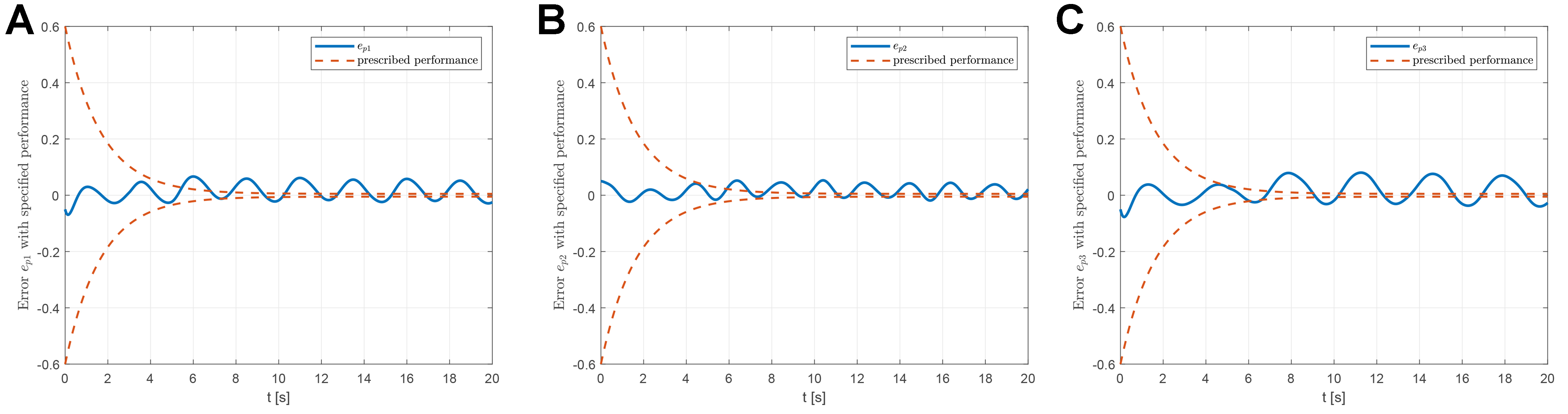
Figure 7. Tracking errors with specified performance under traditional PID control. (A) Attitude tracking error
For a more rigorous quantitative evaluation, the integral of squared error (ISE) and integral of time-weighted absolute error (ITAE) are calculated and summarized in Table 1. The results show that the proposed method achieves substantially improved tracking performance, with markedly lower ISE values compared to the PID baseline. Notably, the ITAE values obtained by the proposed controller are significantly reduced, indicating that the RL mechanism can suppress transient oscillations caused by actuator faults more rapidly and effectively than conventional control.
Quantitative comparison of tracking performance metrics
| Metric | Control scheme | Channel 1 | Channel 2 | Channel 3 |
| ISE: Integral of squared error; RL: reinforcement learning; PID: proportional-integral-derivative; ITAE: integral of time-weighted absolute error. | ||||
| ISE | Proposed RL-based fault-tolerant attitude control | 0.0060 | 0.0089 | 0.0072 |
| Traditional PID | 0.0219 | 0.0131 | 0.0336 | |
| ITAE | Proposed RL-based fault-tolerant attitude control | 0.6799 | 0.6817 | 0.6691 |
| Traditional PID | 5.5052 | 4.0884 | 7.3136 | |
To verify the effectiveness and feasibility of the proposed RL-based fault-tolerant attitude control scheme, comparative simulations are conducted under three scenarios: (1) fault-tolerant control with actuator faults; (2) fault-free control; and (3) control without fault-tolerant under faults. The tracking results for these scenarios are presented in Figures 8–10. The proposed controller achieves accurate tracking despite the presence of actuator faults, with behavior closely matching the fault-free case. In contrast, the uncompensated faulty system exhibits noticeable tracking errors. These results demonstrate the capability of the fault-tolerant strategy to compensate for actuator faults and maintain reliable tracking performance.
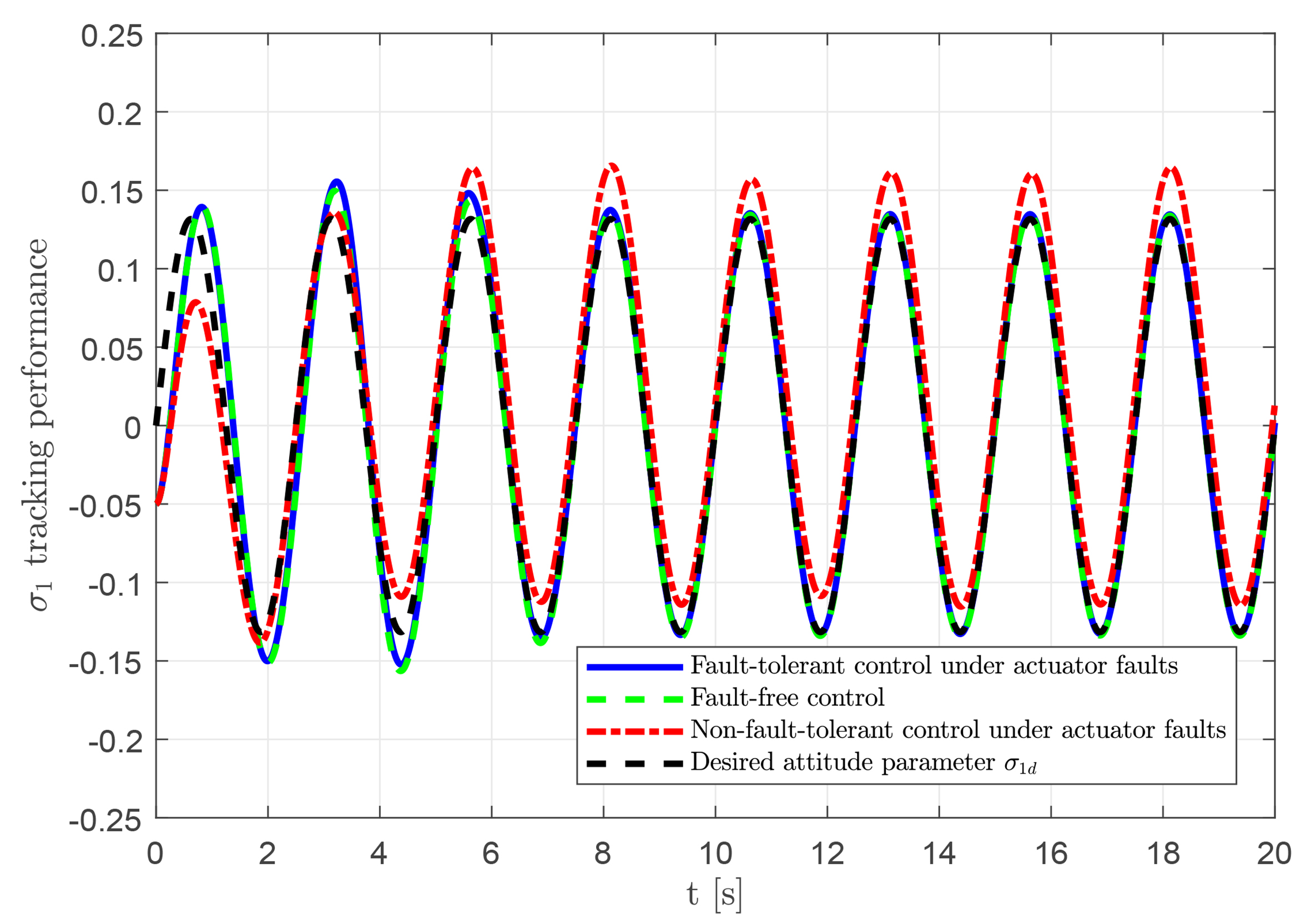
Figure 8. Tracking performance of
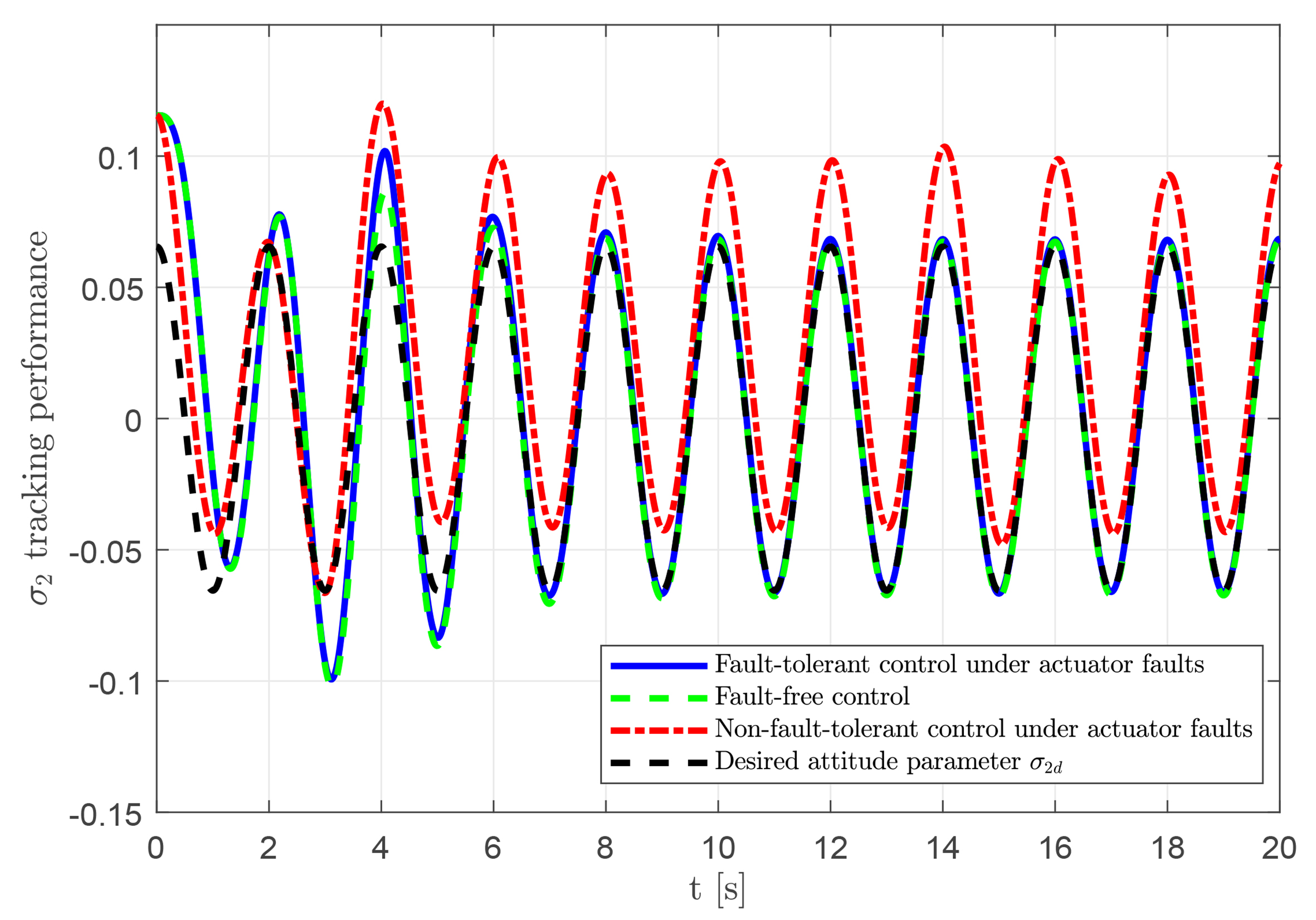
Figure 9. Tracking performance of
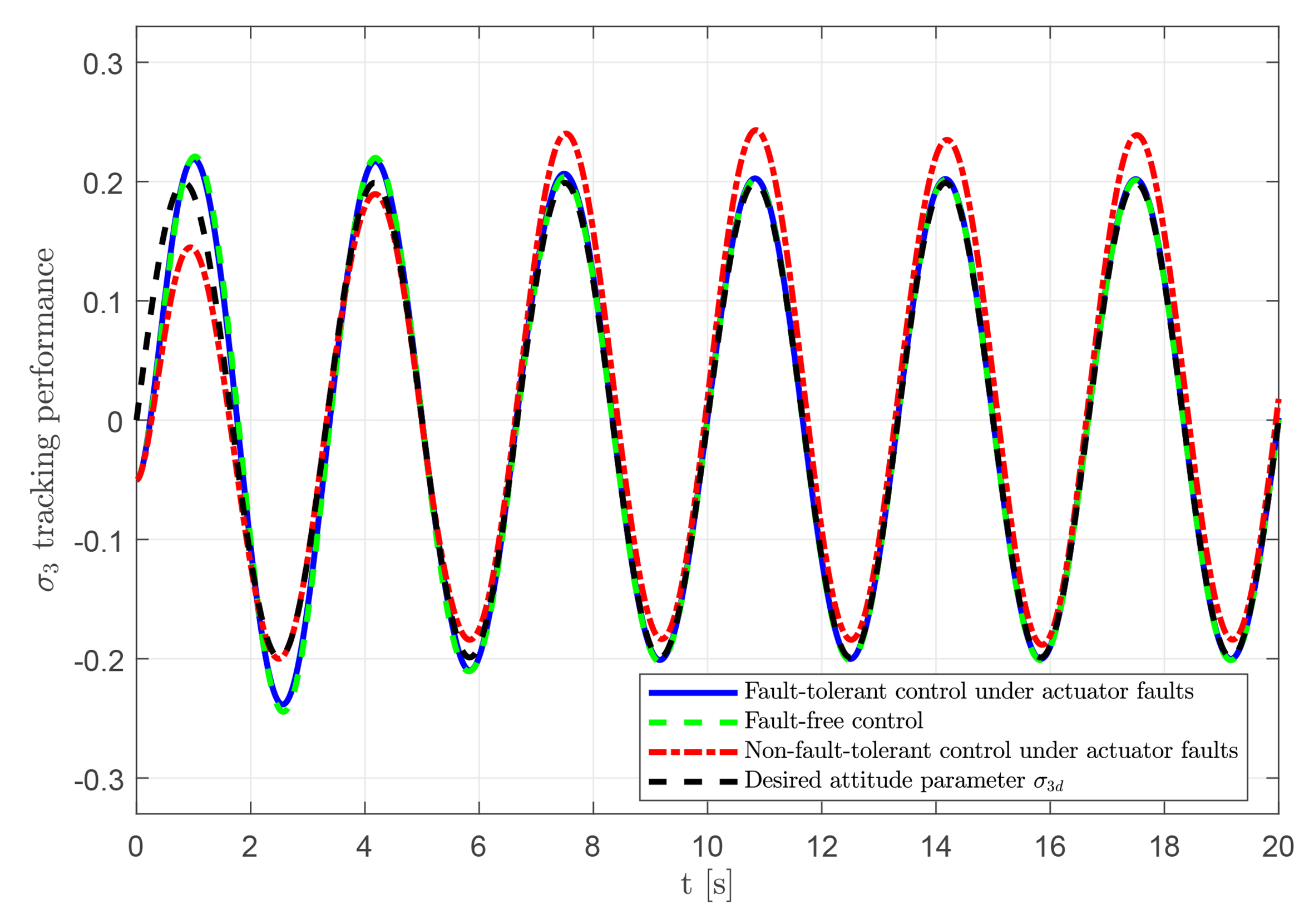
Figure 10. Tracking performance of
In addition, the designed control signal is compared with the actual control input applied, as shown in Figure 11. It can be observed that the control torque remains relatively stable under fault-free conditions. When actuator malfunctions occur at 3 and 5 s, the torque is quickly compensated to maintain system stability. These results indicate that the proposed controller remains effective both in the presence and absence of actuator faults. To investigate the influence of varying design parameters, we further examine the relationship between parameter selection and control performance. Some results are shown in Figures 12 and 13. Specifically, Figure 12A-C illustrate the tracking error comparisons for
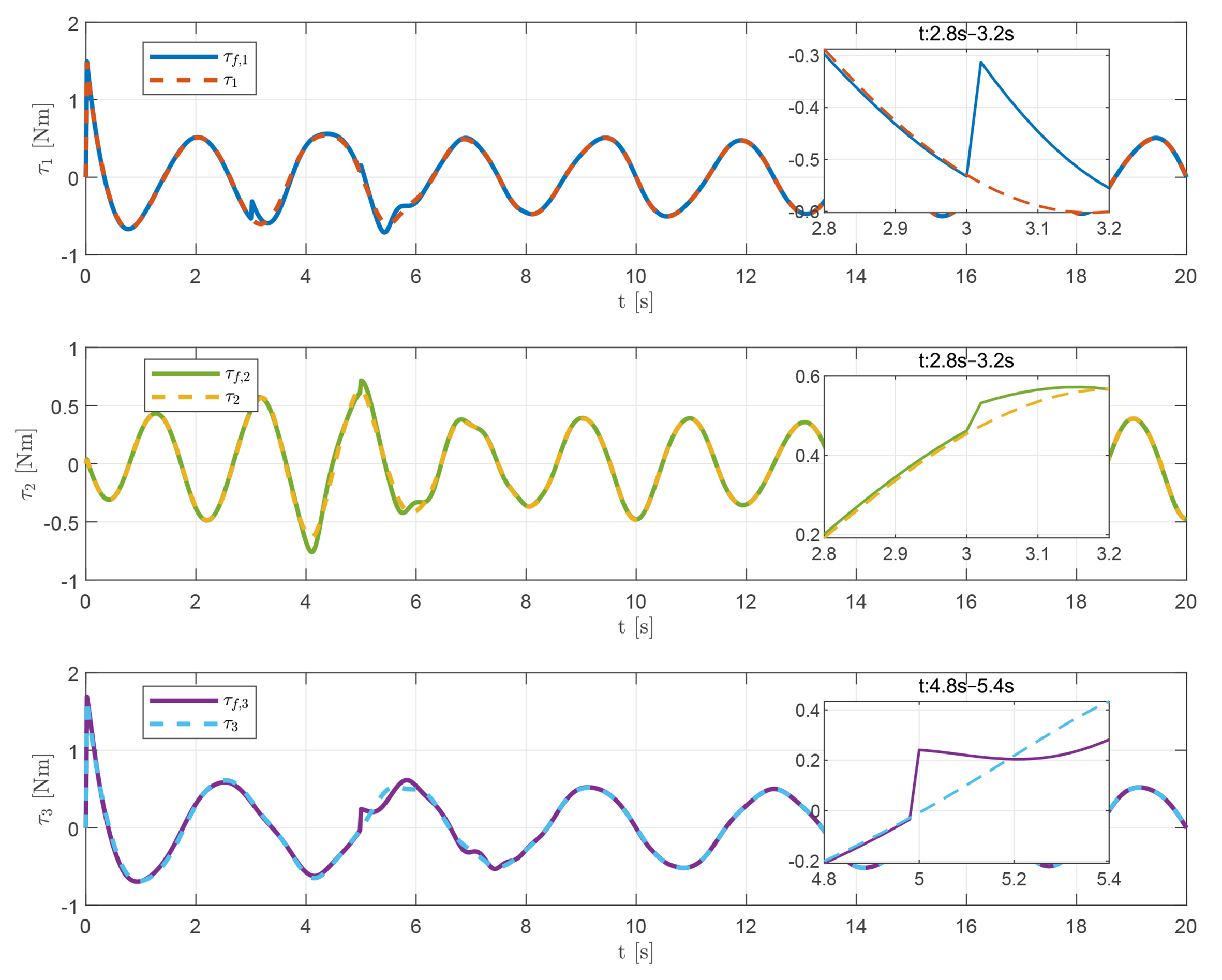
Figure 11. Comparison between the actual control input
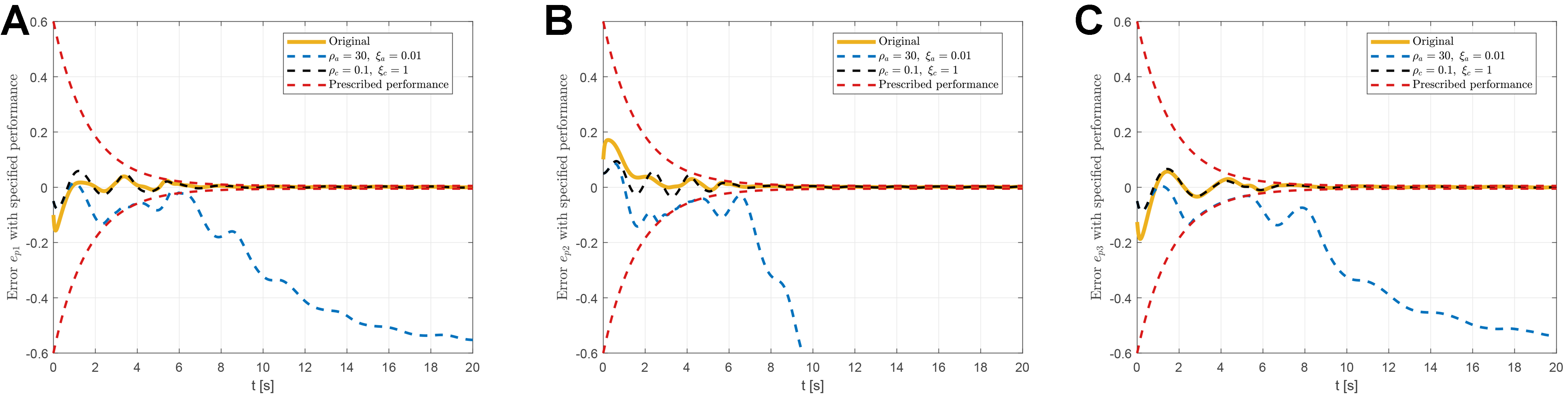
Figure 12. Impact of updating law parameters on attitude tracking performance: (A) tracking error
Figure 13. Attitude tracking error
Additionally, as shown in Figure 13, the tracking performance of the UAV system can be guaranteed under appropriately selected prescribed performance parameters. Conversely, when
5. CONCLUSIONS
In this paper, a RL-based fuzzy logic fault-tolerant attitude control strategy is proposed for a quadrotor UAV system subject to prescribed performance requirements and actuator faults. To satisfy the performance constraints, a smooth error transformation is introduced to ensure that the tracking errors remain within the desired limits. Within the AC architecture-based RL algorithm, in the critic component, an FLS is used to approximate the value function for performance evaluation and to provide a reinforcement signal. In the actor component, an FLS is employed to generate the control input based on the reinforcement signal. With the proposed fuzzy adaptive fault-tolerant attitude control scheme, the stability of the closed-loop UAV system is guaranteed using Lyapunov stability theory, even in the presence of system uncertainties, performance constraints, and actuator faults. Finally, simulations of the quadrotor UAV system are conducted, and the results demonstrate that the proposed RL-based fuzzy adaptive fault-tolerant attitude control strategy is effective and feasible.
DECLARATIONS
Authors' contributions
Conceived the research concept, designed the methodology, established the simulation platform, drafted the original manuscript, prepared the visualizations, and obtained funding support: Ouyang, Y.
Participated in data analysis, performed the main simulations, conducted simulation validation, contributed to drafting the original manuscript, and revised the manuscript: Ma, C.
Conducted data curation, assisted in result analysis, performed data visualization, and polished the manuscript: Wang, Y.
Provided technical support, assisted in establishing the simulation platform, and revised the manuscript: Su, Y.
Supervised the entire project, managed project administration, thoroughly reviewed and edited the manuscript, and validated all results: He, X.
Availability of data and materials
The data supporting the findings of this study are available from the corresponding author upon reasonable request.
AI and AI-assisted tools statement
Not applicable.
Financial support and sponsorship
This work was supported by the National Natural Science Foundation of China (Grant Nos. 62303008, 62303012, 62495083, and 62236002).
Conflicts of interest
All authors declared that there are no conflicts of interest.
Ethical approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Copyright
© The Author(s) 2026.
REFERENCES
1. Huang, H.; He, W.; Chen, Z.; Niu, T.; Fu, Q. Development and experimental characterization of a robotic butterfly with a mass shifter mechanism. Biomimetic. Intell. Robot. 2022, 2, 100076.
2. He, W.; Mu, X.; Zhang, L.; Zou, Y. Modeling and trajectory tracking control for flapping-wing micro aerial vehicles. IEEE/CAA. J. Autom. Sin. 2021, 8, 148-56.
3. Wu, C.; Xiao, Y.; Zhao, J.; Cui, F.; Wu, X.; Liu, W. JingWei: a waterfowl-inspired flapping-wing robot with multimodal aerial-aquatic mobility. IEEE. Robot. Autom. Lett. 2025, 10, 11046-53.
4. Chen, Y.; Pérez-Arancibia, N. O. Adaptive control of a VTOL uncrewed aerial vehicle for high-performance aerobatic flight. Automatica 2024, 159, 109922.
5. Zheng, Z.; Li, J.; Guan, Z.; Zuo, Z. Constrained moving path following control for UAV with robust control barrier function. IEEE/CAA. J. Autom. Sin. 2023, 10, 1557-70.
6. Xu, B.; Suleman, A.; Shi, Y. A multi-rate hierarchical fault-tolerant adaptive model predictive control framework: theory and design for quadrotors. Automatica 2023, 153, 111015.
7. Dong, F.; Yuan, B.; Zhao, X.; Ding, Z.; Chen, S. Adaptive robust constraint-following control for morphing quadrotor UAV with uncertainty: a segmented modeling approach. J. Franklin. Inst. 2024, 361, 106678.
8. Zhao, Z.; Zhang, J.; Liu, Z.; He, W.; Hong, K. S. Adaptive quantized fault-tolerant control of a 2-DOF helicopter system with actuator fault and unknown dead zone. Automatica 2023, 148, 110792.
9. Zhao, W.; Liu, H.; Lewis, F. L. Data-driven fault-tolerant control for attitude synchronization of nonlinear quadrotors. IEEE. Trans. Autom. Control. 2021, 66, 5584-91.
10. Liu, Y.; Dong, X.; Shi, P.; Ren, Z.; Liu, J. Distributed fault-tolerant formation tracking control for multiagent systems with multiple leaders and constrained actuators. IEEE. Trans. Cybern. 2023, 53, 3738-47.
11. Ma, Y.; Jiang, B.; Wang, J.; Gong, J. Adaptive fault-tolerant formation control for heterogeneous UAVs-UGVs systems with multiple actuator faults. IEEE. Trans. Aerosp. Electron. Syst. 2023, 59, 6705-16.
12. Hu, Y.; Yan, H.; Wang, M.; Hu, X.; Li, Z. Fuzzy observer-based input/output event-triggered control for Euler–lagrange systems with guaranteed performance and input saturation. IEEE. Trans. Fuzzy. Syst. 2024, 32, 2077-88.
13. Ren, Y.; Sun, Y.; Liu, Z.; Lam, H. K. Parameter-optimization-based adaptive fault-tolerant control for a quadrotor UAV using fuzzy disturbance observers. IEEE. Trans. Fuzzy. Syst. 2025, 33, 593-605.
14. Kong, L.; He, W.; Yang, C.; Li, Z.; Sun, C. Adaptive fuzzy control for coordinated multiple robots with constraint using impedance learning. IEEE. Trans. Cybern. 2019, 49, 3052-63.
15. Zhang, F.; Dai, P.; Na, J.; Gao, G.; Shi, Y.; Liu, F. Adaptive fuzzy tracking control for a class of uncertain nonlinear systems with improved prescribed performance. IEEE. Trans. Fuzzy. Syst. 2025, 33, 1133-45.
16. Yu, D.; Ma, S.; Liu, Y. J.; Wang, Z.; Chen, C. L. P. Finite-time adaptive fuzzy backstepping control for quadrotor UAV with stochastic disturbance. IEEE. Trans. Autom. Sci. Eng. 2024, 21, 1335-45.
17. Su, M.; Pu, R.; Wang, Y.; Yu, M. A collaborative siege method of multiple unmanned vehicles based on reinforcement learning. Intell. Robot. 2024, 4, 39-60.
18. Dong, L.; He, Z.; Song, C.; Sun, C. A review of mobile robot motion planning methods: from classical motion planning workflows to reinforcement learning-based architectures. J. Syst. Eng. Electron. 2023, 34, 439-59.
19. Zhang, H.; He, L.; Wang, D. Deep reinforcement learning for real-world quadrupedal locomotion: a comprehensive review. Intell. Robot. 2022, 2, 275-97.
20. Wen, G.; Yu, D.; Zhao, Y. Optimized fuzzy attitude control of quadrotor unmanned aerial vehicle using adaptive reinforcement learning strategy. IEEE. Trans. Aerosp. Electron. Syst. 2024, 60, 6075-83.
21. Wen, G.; Niu, B. Optimized distributed formation control using identifier–critic–actor reinforcement learning for a class of stochastic nonlinear multi-agent systems. ISA. Trans. 2024, 155, 1-10.
22. Han, M.; Zhang, L.; Wang, J.; Pan, W. Actor-critic reinforcement learning for control with stability guarantee. IEEE. Robot. Autom. Lett. 2020, 5, 6217-24.
23. Ouyang, Y.; Xue, L.; Dong, L.; Sun, C. Neural network-based finite-time distributed formation-containment control of two-Layer quadrotor UAVs. IEEE. Trans. Syst. Man. Cybern. Syst. 2022, 52, 4836-48.
24. Ouyang, Y.; Sun, C.; Dong, L. Actor–critic learning based coordinated control for a dual-arm robot with prescribed performance and unknown backlash-like hysteresis. ISA. Trans. 2022, 126, 1-13.
25. Zhou, Z. G.; Zhou, D.; Chen, X.; Shi, X. N. Adaptive actor-critic learning-based robust appointed-time attitude tracking control for uncertain rigid spacecrafts with performance and input constraints. Adv. Space. Res. 2023, 71, 3574-87.
26. Han, H.; Cheng, J.; Xi, Z.; Lv, M. Symmetric actor–critic deep reinforcement learning for cascade quadrotor flight control. Neurocomputing 2023, 559, 126789.
27. Yang, S.; Pan, Y.; Cao, L.; Chen, L. Predefined-time fault-tolerant consensus tracking control for Multi-UAV systems with prescribed performance and attitude constraints. IEEE. Trans. Aerosp. Electron. Syst. 2024, 60, 4058-72.
28. Yu, Z.; Li, J.; Xu, Y.; Zhang, Y.; Jiang, B.; Su, C. Y. Reinforcement learning-based fractional-order adaptive fault-tolerant formation control of networked fixed-wing UAVs with prescribed performance. IEEE. Trans. Neural. Netw. Learn. Syst. 2024, 35, 3365-79.
29. Aforozi, T. A.; Rovithakis, G. A. Prescribed performance tracking for uncertain MIMO pure-feedback systems with unknown and partially nonconstant control directions. IEEE. Trans. Autom. Control. 2024, 69, 7285-92.
30. Wang, X.; Kong, L.; Meng, T.; Xia, J.; He, W. Event-triggered tracking control for a flapping-wing aerial vehicle with prescribed performance. IEEE. Trans. Aerosp. Electron. Syst. 2025, 61, 17476-87.
31. Li, Z.; Wang, X.; Guo, H.; Xi, L.; Liu, G.; Li, Y. Distributed output feedback prescribed performance control for high-order nonlinear multi-agent systems. IEEE. Trans. Autom. Sci. Eng. 2025, 22, 12730-40.
32. Li, D.; Ma, G.; Li, C.; He, W.; Mei, J.; Ge, S. S. Distributed attitude coordinated control of multiple spacecraft with attitude constraints. IEEE. Trans. Aerosp. Electron. Syst. 2018, 54, 2233-45.
33. Ouyang, Y.; Dong, L.; Wei, Y.; Sun, C. Neural network based tracking control for an elastic joint robot with input constraint via actor-critic design. Neurocomputing 2020, 409, 286-95.
34. Wang, X.; Wang, Q.; Sun, C. Prescribed performance fault-tolerant control for uncertain nonlinear MIMO system using actor–critic learning structure. IEEE. Trans. Neural. Netw. Learn. Syst. 2022, 33, 4479-90.
Cite This Article
How to Cite
Download Citation
Export Citation File:
Type of Import
Tips on Downloading Citation
Citation Manager File Format
Type of Import
Direct Import: When the Direct Import option is selected (the default state), a dialogue box will give you the option to Save or Open the downloaded citation data. Choosing Open will either launch your citation manager or give you a choice of applications with which to use the metadata. The Save option saves the file locally for later use.
Indirect Import: When the Indirect Import option is selected, the metadata is displayed and may be copied and pasted as needed.
About This Article
Special Topic
Copyright

Data & Comments
Data
0













Comments
Comments must be written in English. Spam, offensive content, impersonation, and private information will not be permitted. If any comment is reported and identified as inappropriate content by OAE staff, the comment will be removed without notice. If you have any queries or need any help, please contact us at [email protected].