



fig2
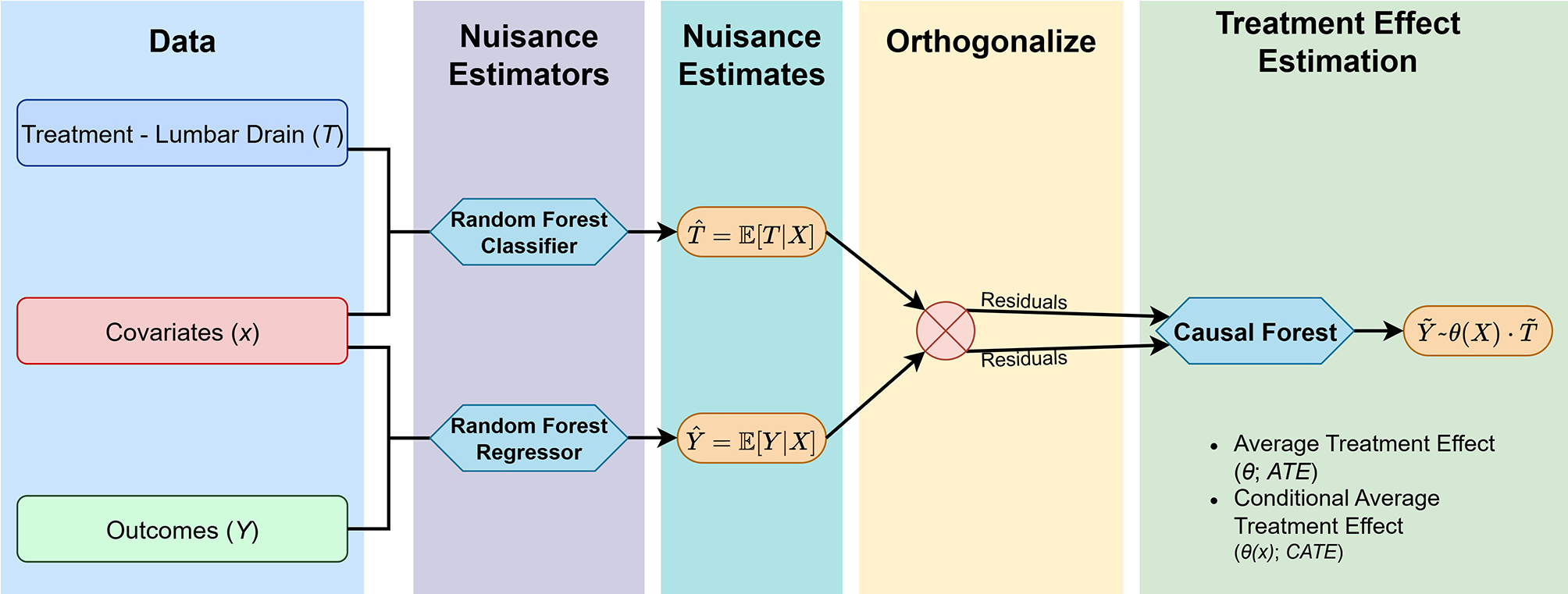
Figure 2. Double Machine Learning (DML) workflow. The pipeline begins with input data comprising treatment assignment, covariates, and outcomes. Nuisance functions for treatment and outcome models are estimated using random forests. These predictions are then orthogonalized by computing residuals, which are then passed to a causal forest algorithm that estimates both the average treatment effect (ATE), and the conditional average treatment effect (CATE).




